

【制作したきっかけ】
zennやqiita、Xなどで収集した記述記事を一元管理するアプリが欲しいなと思ったことと。いままではPasSにデプロイしてきましたが自分でインフラを構築してIaaSにデプロイしたかったこと。大規模なシステム開発でしばしば用いられるAWS、サーバーを意識せずアプリケーション開発のみに集中することができるサーバーレスアーキテクチャに興味があったことなどが理由で作成しました。
【説明】
このアプリは技術記事を一元管理することを目的としており技術記事の作成・編集・削除ができます。また、特定の時間になるとバッチ処理によりqiitaのapiをたたくことで記事を自動で取得できます。技術記事のタイトル検索、タグ検索に対応しており自分が見たいタグやタイトルの記事を検索することができます。
【機能】
ホーム画面
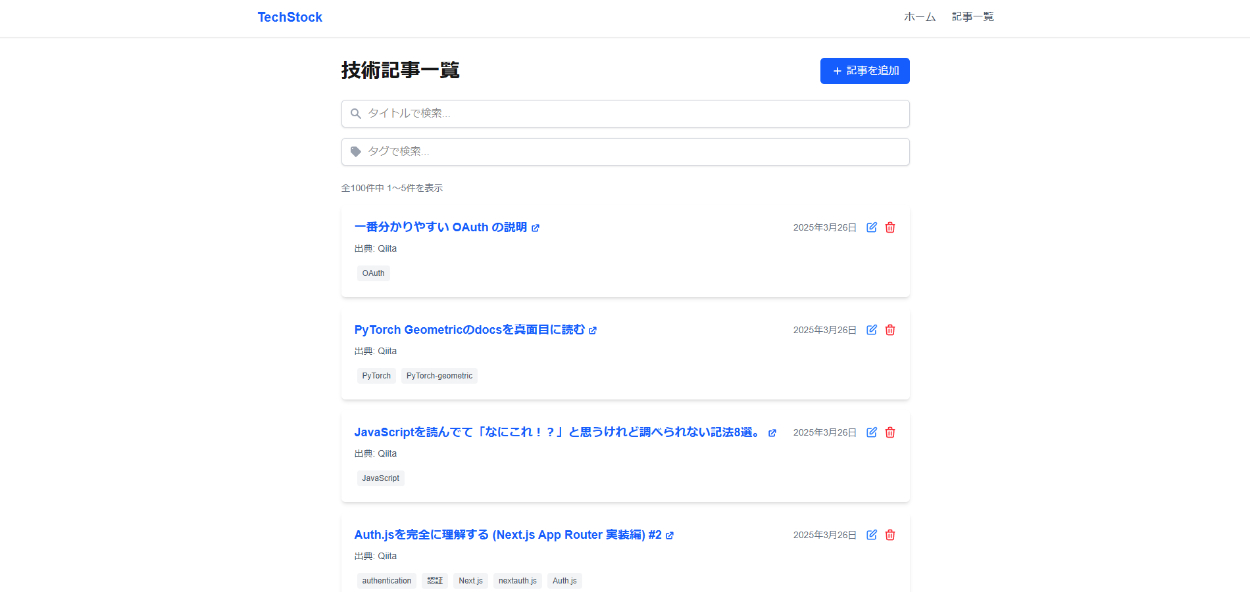
記事一覧
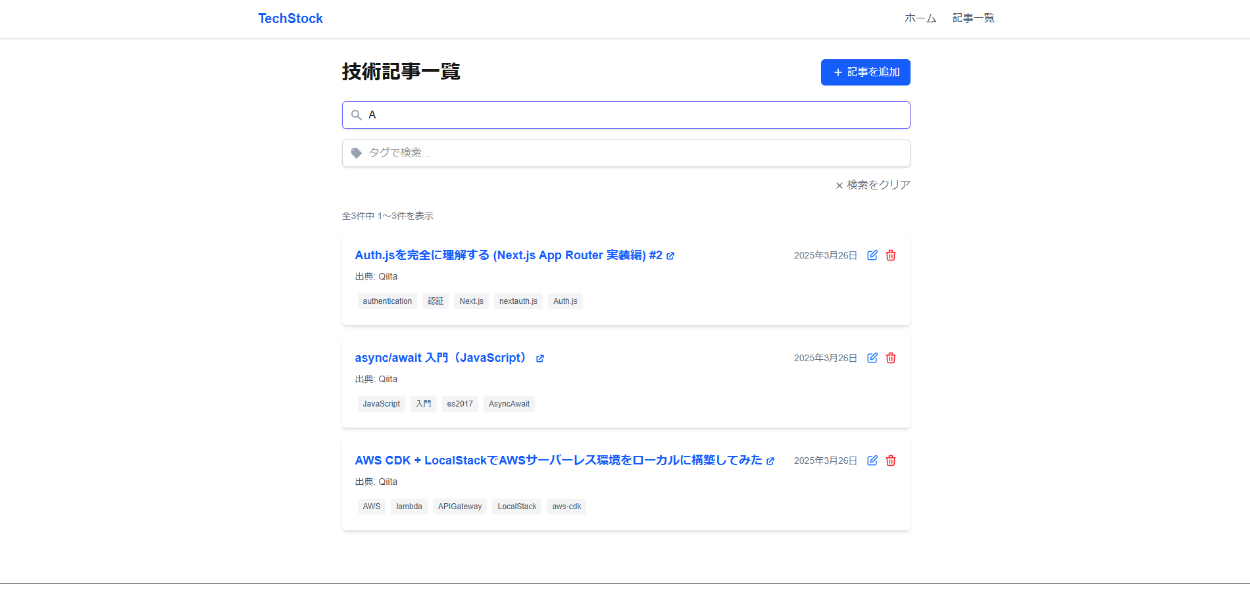
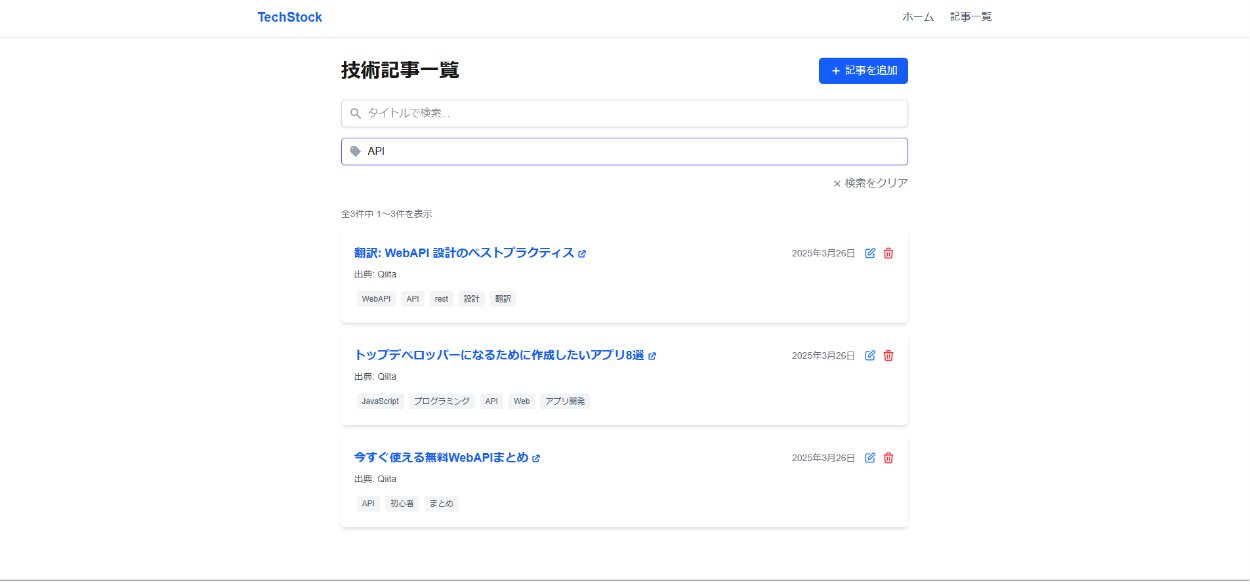
検索 (タグとタイトルで同時に検索も可能です)
検索機能はapiのエンドポイントにクエリパラメーターを設定することで実現しています。具体的には検索欄に記入されたタイトルやタグの情報をフロントエンド側でstateで管理しuseEffectの依存配列にそれらを設定します。タイトルやタグが入力されればuseEffectが走りタグやタイトルをクエリパラメーターとして含んだapiのurlをたたきそれをバックエンド側でハンドルすることで検索機能を実現しています。
 作成モーダル
作成モーダル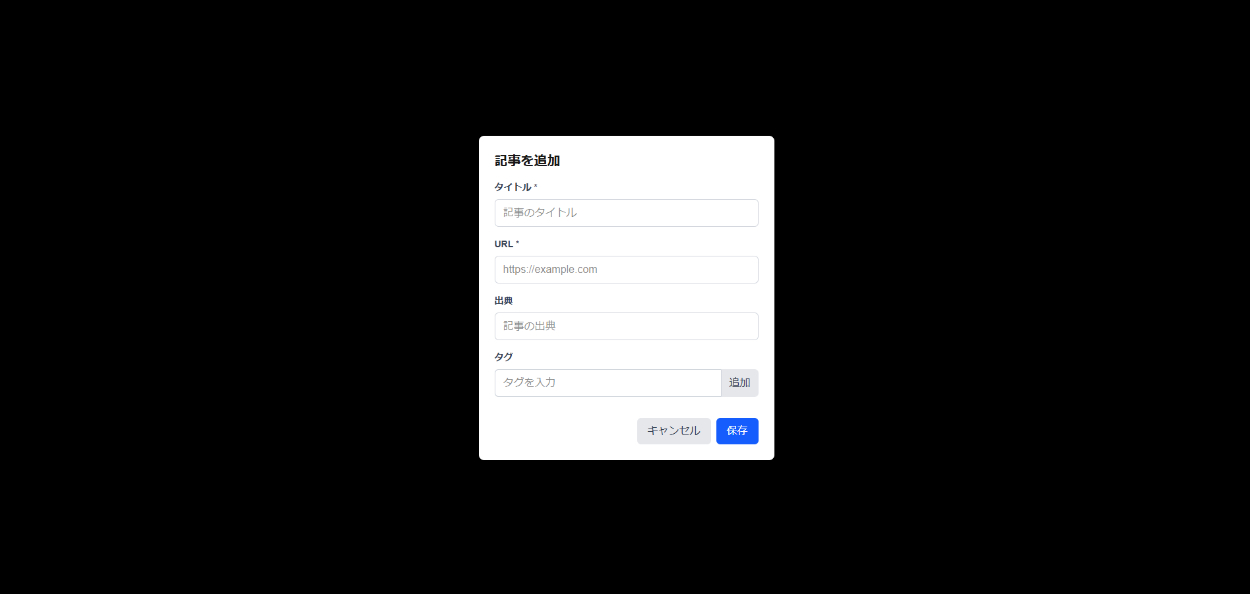
編集モーダル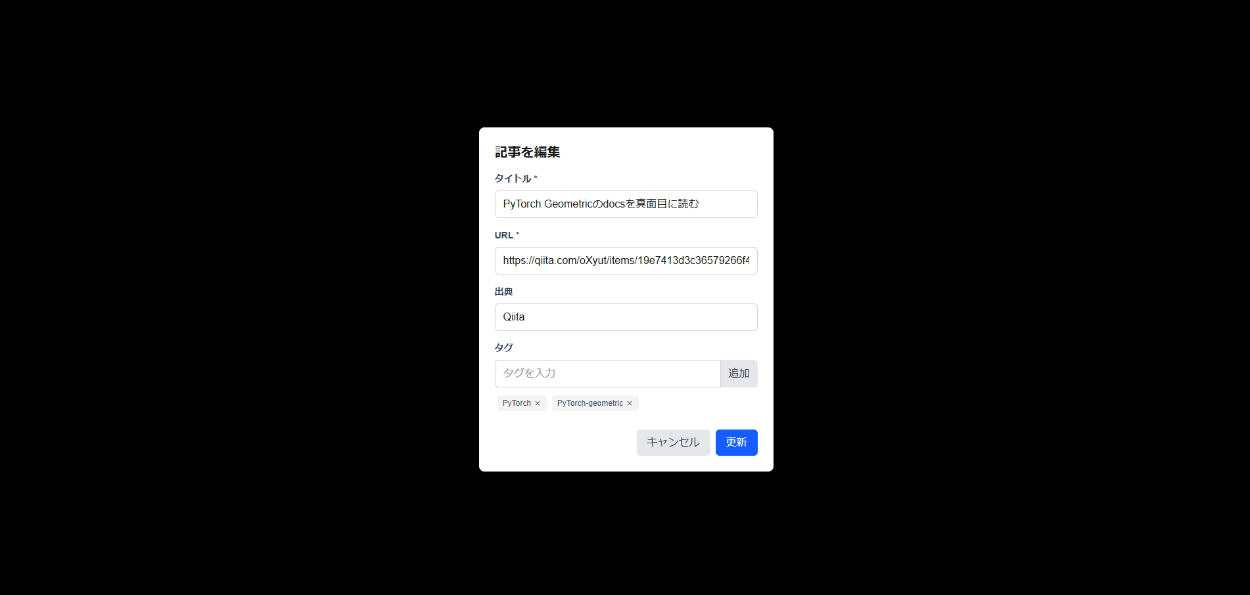
削除
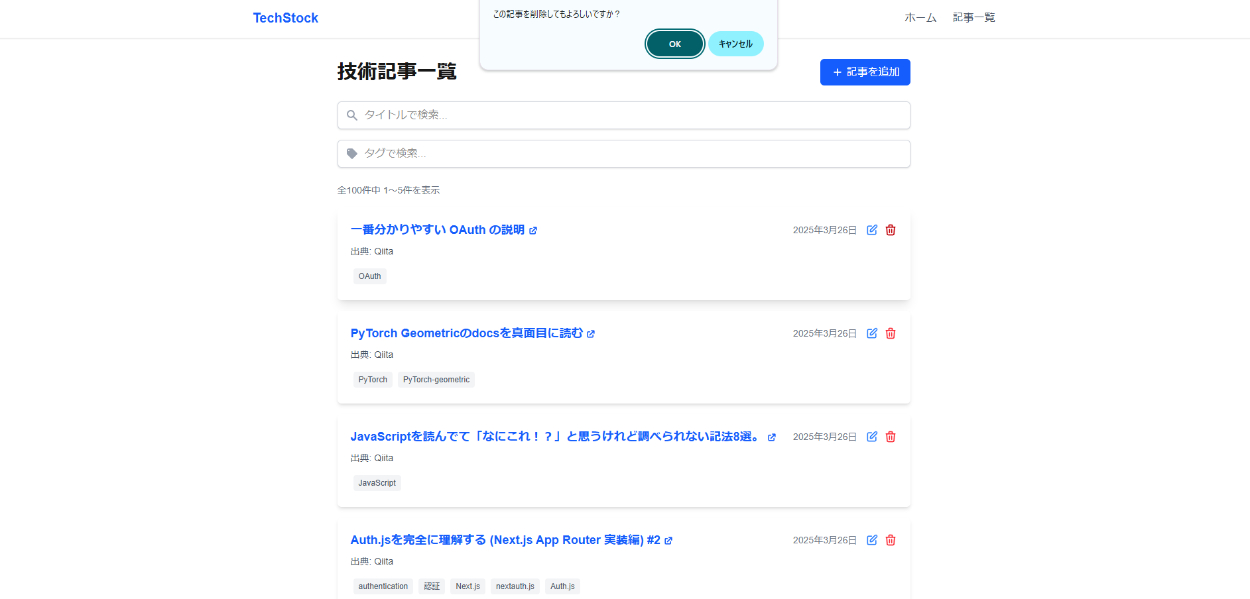
【開発環境】
インフラストラクチャー
使用IaC: AWS CDK + CloudFormation
ローカル開発: LocalStack
使用言語: typescript
いつも開発したアプリはRenderやVercelなどのPaaSにデプロイしてきましたが今回は
自分でインフラを構築してデプロイしたかったことや大規模なシステムを開発する際にしばしば用いられるAWSを体感してみたかったためAWSでインフラを構築しました。
AWS CDKを用いた理由としてはIaCに興味があったことやリソースの削除のし忘れが怖かったのでcdk destoryを用いてスタックを削除することでリソースを一括削除できることも理由の一つでした。同じIaCとして一番のシェアを誇るのがTerafformだと思いますがTerafformの利点はAzureやgoogle cloudなどのほかのプラットフォームのクラウドリソースを管理できる点にあります。しかし、TerafformはAWS CDKよりもリソースの記述にインフラの知識が必要であり今回はAWSのみを使用してインフラを構築する予定だったのでより簡素な記述でインフラを作成できるCDKを採用しました。
また、ローカル環境でawsのサービスをエミュレートできるLocalStackを用いてcdkのデプロイや正しくバックエンドが動いているかを確認しました。
フロントエンドのインフラ構成
フロントエンドの構成はcloudfront + s3としました。この構成はcloudflareには劣りますが静的サイトのデプロイ最安構成の一つとして数えられます。cloudfront (CDN)によりオリジンサーバーの内容がエッジサーバーにキャッシュされることで世界中どこからアクセスしても低レイテンシーでサイトが表示されます。
cloudfrontをspaのように動かすためにカスタムエラーレスポンスの設定が必要でした。
バックエンドのインフラ構成
バックエンドはAPI gatway + lambda + dynamoDBとしました。一般的なバックエンドの構成だと思います。また、今回はqiitaのapiを定期的にたたいて記事を取得するバッチ処理を実装したかったのでEventBridgeでルールを作成してlambda関数を定期的に実行するcronジョブを作成しました。
全体の構成
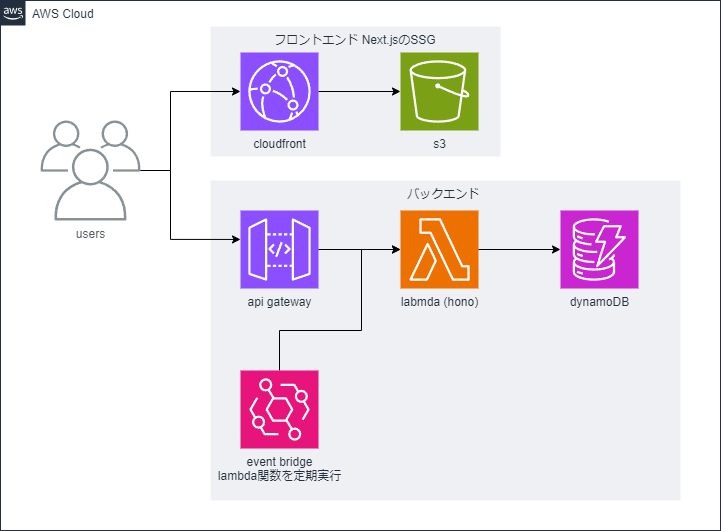
フロントエンド
使用言語: typescript
仕様フレームワーク: Next.js (SSG)
今回はcloudfront + s3 にフロントエンドをデプロイする予定だったのでNext.jsをクライアント側でのみ使用してSSGとしてビルドしました。しかし、後から認証を追加しようとしたときにmiddlewareが使えなかったりawsのcognitoなどもSPA (react)向けのテンプレートがあったりしたことや認証の処理などはNext.jsではサーバ側で行うことが一般的なのでもともとクライアント側でしか動かさないならNext.jsの利点が十分に傍受できないためreact + viteなどの構成のほうが良かったなと思っています。
バックエンド
使用言語: typescript
仕様フレームワーク: hono (aws lambda)
今回はバックエンドとしてhonoを採用しました。採用した理由としては軽量で高速に動作するaws lambda上にデプロイできるバックエンドフレームワークであったことや最近cloudflare上にデプロイできるバックエンドフレームワークとして話題に上がっていたことなどが挙げられます。honoを用いることでhonoで作成したエンドポイントをbuildして簡単にlambda関数としてデプロイ出来ました。
データベース
使用DB: DynamoDB
今回は存分にawsのリソースを使用して開発をするというコンセプトでアプリを開発したので使用するDBはRDSかDynamoDBの二択になります。今回DynamoDBを使用した理由としてはDynamoDBはRDSよりも一貫性に弱くデータが複数のアベイラビリティゾーンに分散配置されているため更新直後のデータが読み込みに反映されないことがあります(強い整合性のオプションもありますがそれならRDSを使用したほうがいいかもしれません)がアプリケーションの仕様上ACIDなどの強い結果整合性が求められるアプリではないこととRDSを用いた際に記事のタグを厳密に管理すると記事とタグが多対多の関係になってしまいリレーショナルデータベースにstringの配列をカラムとして持たせるのもよくないのでNoSQLデータベースのDynamoDBを採用しました。
開発時はawsが公開しているdynamodb localのdocker-composeファイルを用いてdynamodbの検証を行いました。
【開発期間】
1週間
【工夫した点】
AI駆動開発
今話題のCursorエディターを用いて開発を行いました。
今回はバックエンドとインフラに力を入れたかったのでフロントエンドはAIをベースとして作成しました。AIエディターを用いることで通常よりも早いペースで開発することができました。しかし、CursorのAgentモードはしばしば暴走するので適切にAIが生成したコードを理解し必要に応じて修正する必要がありました。また、CDKやhonoの情報は少ないことからAIのコード生成精度が悪かったのでそこらへんは自分で実装しました。
フロントエンド
フロントエンドで工夫した点はAIをフル活用したことです。特にフロントエンドの記述は厳密なデザインを実装しない個人開発ではとても有効でした。
フロントエンドをAIに任せることにより自分はバックエンドやインフラに力を入れることができました。
バックエンド
バックエンドで工夫した点はバッチ処理の記述です。バッチ処理ではqiitaのapiからストックしている記事を取得する必要があるのですがdynamoDBによるI/Oがボトルネックとなりlambdaのデフォルト設定の128MBのメモリ容量と30sの時間制限を超えてしまう問題がありました。なので、apiからのレスポンスとして受け取る内容を必要なもののみ保存するようにmapし書き込みを並列で行うことで問題を解決しました。また、apiから取得した記事がすでにdynamoDBに書き込まれていないかをチェックする記述の際に記事のidを比較する必要がありますがsetというデータ構造を利用することでナイーブな実装ではO(n^2)かかるところをO(nlogn)で処理できるようにしました。しかし、既存の記事を取得するのにdynamoDBのスキャンというコストが高い処理を行っているのでもし記事が今後1万件や10万件に増えてきたときに対応しきれなくなってしまうことが考えられるのでもう少し改善の余地があるような気がします。
そのほかにはEventBridgeによる定期実行処理があげられます。EventBridgeがlambda関数にある時間帯になったらイベントを発行しそれをhonoのlambda用のハンドラーでハンドルすることによりバッチ処理用の処理を実行することができます。あとからZennやStack-overflowなどの他のサービスとも簡単に連携できるようにapi gatewayに載せるエンドポイントとは隔離して作成しました。
CI
github actionsでプルリクエスト作成時にcdk diffを実行しプルリクエスト作成時点でデプロイ時にエラーが発生しないかどうかや追加したリソース・変更点が正しいかを確認します。
CD
github actionsでmainブランチにpushされるとフロントエンドのビルドとバックエンドのビルドが走り自動でフロントエンドとバックエンドのリソースがデプロイされます。
DB
DBで工夫した点はテーブル構造とGSIの設定にあります。
今回は記事をタイトルやタグで検索したいという機能要件がありました。
それを実現するために必要だったのがテーブルの工夫です。dynamoDBは前方一致検索やstringをlistとして保持しlist内にあるタグがあるかで検索する機能がありますがそれらは大文字と小文字を区別しませんでした。しかし、記事一覧に表示される文字を小文字や大文字に統一するのはいやだったのでカラムとして元のタグやタイトル情報のほかに小文字統一したタグとタイトルを持たせることにより表示は元の記述で検索は作成した小文字統一の記載で行うことができます。今回はフロントエンド側で送られてきたデータをバックエンド側で小文字にして作成したカラムで検索をかけることで検索機能を実現しています。
もう一つの工夫はGSIの設定です。タイトルにGSIを設定することでタイトルでの検索をより高速に実行できます。ほかの方法としてはタイトルをソートキーとして設定することが挙げられますがソートキーはidと同時に使用しないといけないことや同じパーティションキーでソートや検索をかけたかったわけではないためGSIを作成しました。
プリコミットhook
lint-staged + huskyによるプリコミットhookを作成することでコミット時にeslintによる静的解析とフォーマットをかけることによりコードを常にクリーンに保ちます。
【改善点】
フロントエンド
フロントエンドの改善点は検索時の遅延です。検索を実行した際にわずかにですがページがフリーズします。また、記事作成時や更新時にも若干の遅延が発生するため別途処理が必要だと感じました。また、s3でデプロイする際にNext.jsのビルド時の環境変数の優先順位を勘違いしておりかなり苦戦しました。追加の設定としてはRoute53による独自ドメインの取得やWAFの設定などが挙げられます。
バックエンド
バックエンドでの改善点はhonoのRPC機能を活用できていないことです。honoの特徴の一つとしてフロントエンドとバックエンドの型を共有する強力なRPC機能が挙げられますが今回はNext.jsをクライアント側でのみ動かすという形で使用したため十分にRPC機能を活用することができませんでした。また、honoの環境変数周りで苦戦してしまいました。また、CORSの設定でcloudfrontとの通信がうまくいかずかなり苦戦しました。
加えて前述したとおり今後記事が増えていくことを考えたらqiitaの記事取得の際の重複排除処理をもっと工夫しないといけないと思います。
インフラストラクチャー
インフラストラクチャーでの改善点はセキュリティの弱さです。
今回のapiやcloudfrontのディストリビューションは特に制限をかけていないため誰でもアクセスすることができます。cloudfrontでは簡単なBasic認証からcognitoでのログイン機能の追加、api gatewayではlambda関数による認証やcognitoでの認証を追加することが改善点として挙げれらます。また、EventBridgeの定期実行時間をローカルタイムゾーン(本来はUTC) と勘違いしており処理が実行されずに苦戦してしまいました。
【まとめ】
今回はAWSのリソースを存分に活用しアプリケーションを作成しインフラの構築を体感することができました。また、マネジメントコンソールを使用してアプリケーションを作成するよりもcdk deployで一括でデプロイできる便利さを実感しました。CI/CDなどはもっと実際の開発に寄せるとstaging環境やdevlop環境ごとに異なるjobを走らせないといけなかったりほかにもテストの作成なども行わないといけないですが簡易的にでもdevOpsを体感することができました。アプリは従量課金が怖いので削除しています。cloudformationがcdk用のs3をいじくるのでs3の無料枠を超えそうになっています。