

目次
1. 機能一覧
2. テーブル設計
3. 工夫した点
4. 振り返り
① 機能一覧と詳細
ユーザー登録 / ログイン
TOPページ
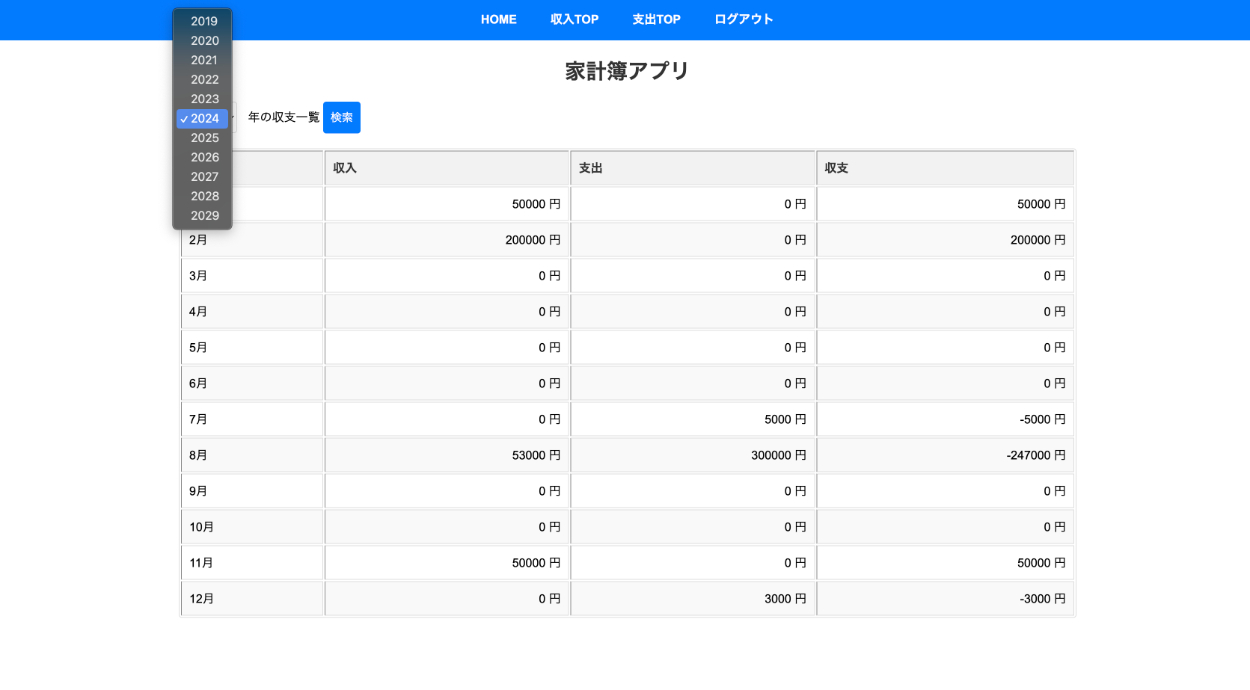
収入 / 収入源のCRUD機能
支出 / 支出カテゴリのCRUD機能
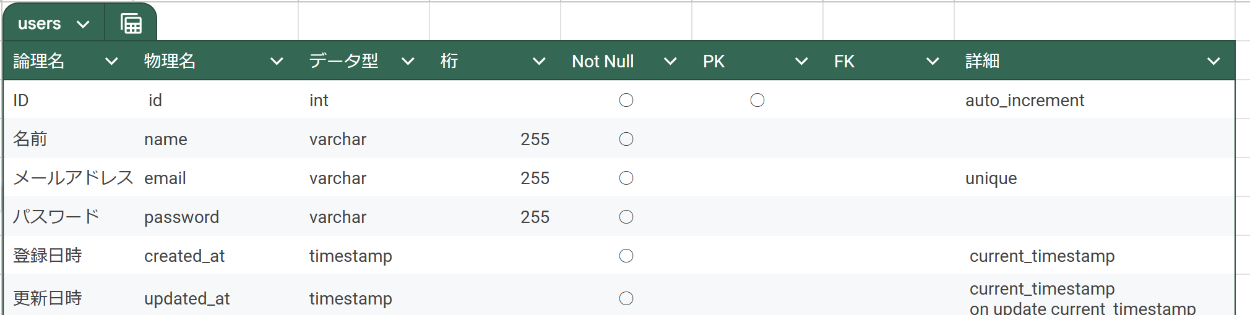
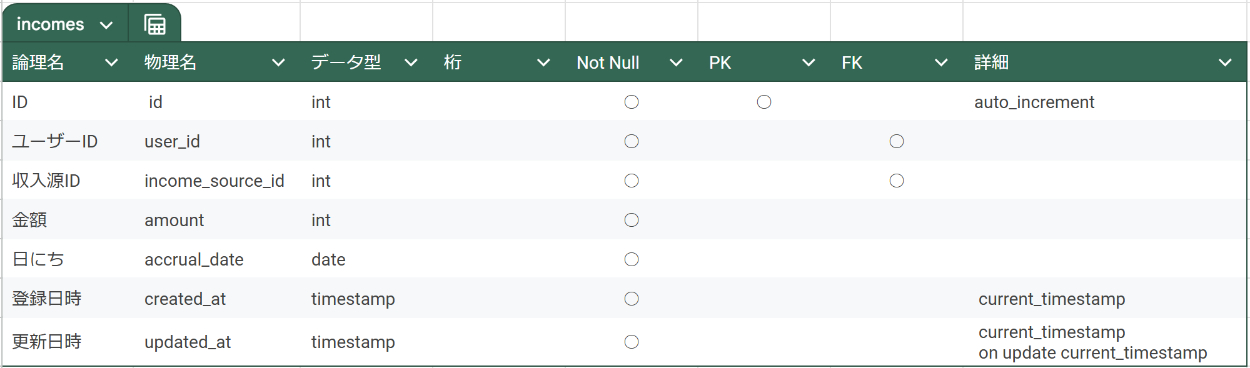
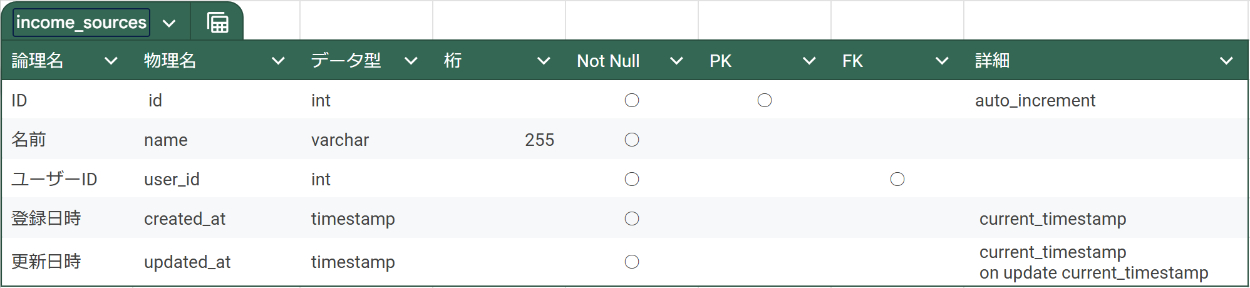
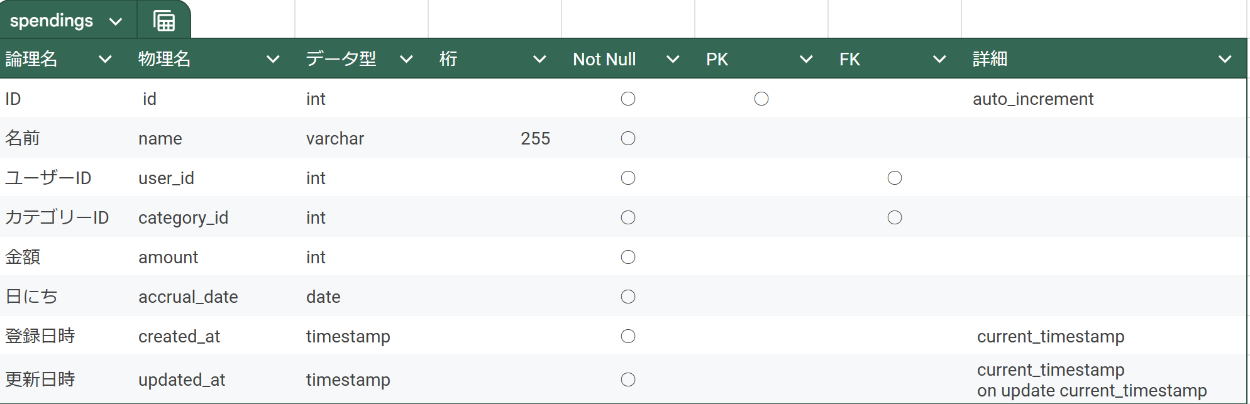
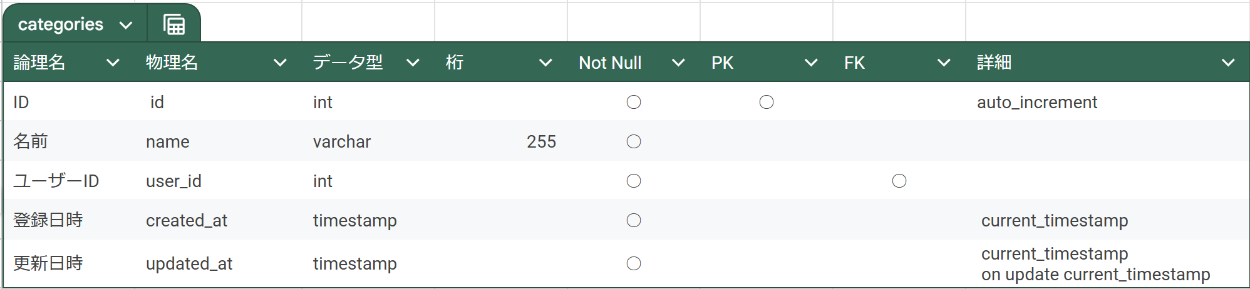
② テーブル設計
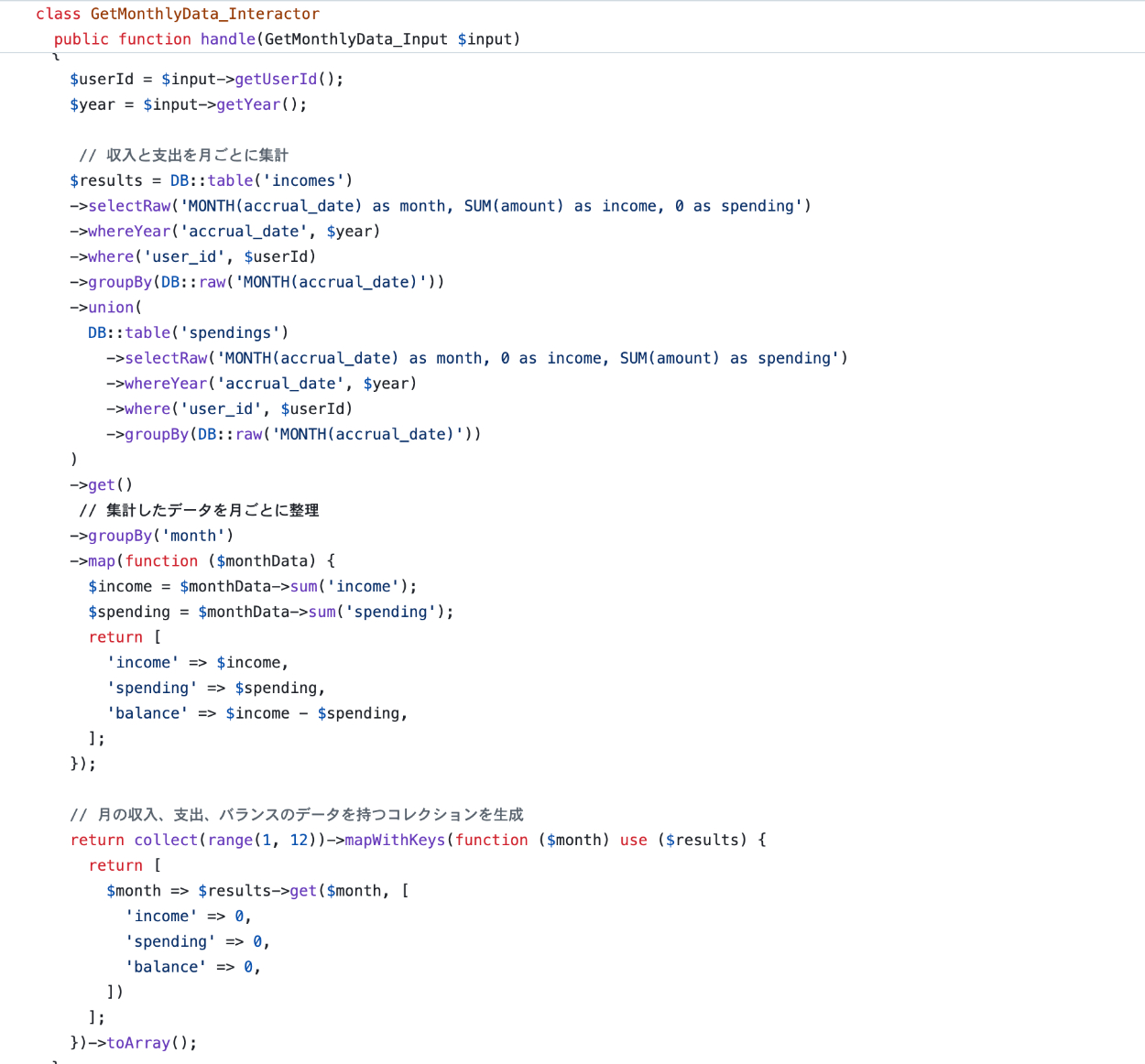
③ 工夫した点
収支の計算処理の効率化
- 収入と支出のデータを集計する際、UNION を活用することで、1回のクエリで収入と支出のデータをまとめて取得。不要なクエリ発行を削減し、効率的なデータ取得が可能。
④ 振り返り
学んだこと
N+1問題 の回避
リファクタ前→各月ごとに収入と支出に対して個別にクエリを実行しているため、12か月分のデータを取得する場合、12×2=24回のクエリが発生し、パフォーマンスが低下。

リファクタ後→各月ごとに実行するのではなく、収入と支出をそれぞれ1回のクエリで取得。1年分のデータを効率よく取得でき、パフォーマンスの向上。しかし可読性や効率性の余地があるため、さらなるリファクタリングとSQLの理解が必要。
今後の課題
1. クラスとメソッドの命名規則
・冗長なプレフィックスやアンダースコアを含む命名があり、コードの一貫性と可読性を損ねている。命名規則を統一し、より直感的でわかりやすい名前に変更する。
2. クラスやインターフェースでの責務の分離
ビジネスロジックがUseCase層に集中しているため、開発規模やロジックの複雑性に応じてRepository層やInfrastructure層を適切に分離し、各層の責務を明確にする。
GitHub