
アプリの概要
LibConeは、企業内の書籍の貸出、社員への書籍購入補助(福利厚生)をシステム化するアプリケーションです。ただシステム化するだけでなく、社員同士の「connection」ができるのがこのアプリです。このアプリを通じて社員は「書籍を読んだ上で得た知識や考え」・「自分の学習履歴」を共有し合ったり、書籍購入に必要な「special_pointをプレゼント」し合えたりします。special_pointは書籍への口コミや評価をすると獲得できる仕組みになっているため、社員の学習意欲向上が狙えます。
「憧れのあの先輩はこんな書籍を読んできたのか」「新卒のあの人にpointギフトするか」「みんな書籍で学習しているし自分も学ぼうかな」といった気持ちになるような企業文化を作ることが目標です。
機能概要
社員向け機能
- 登録・認証
- 社員としての登録、ログイン、ログアウト機能
- 書籍の貸出と返却
- 書籍バーコードをスキャンし、書籍情報を自動取得。借りたい場合は「借りるボタン」で貸出履歴が記録され、返却時はアプリ内から「返却ボタン」で返却が記録されます。
- 書籍一覧の参照
- 社内の書籍一覧、貸出情報、貸出者履歴、社内書籍口コミを閲覧可能
- 楽天bookAPIで取得した書籍の中から購入リクエストができて、それらは管理者へ通知される。購入リクエストをする際にuserが所持しているpoint(1pt=1円)を消費する。月毎にchargeされ1ヶ月経つと消えるmonth_pointと,口コミ投稿で得られるspecial_pointが存在。
- 評価と口コミ
- 社内図書に対し、5段階評価と口コミを投稿可能。口コミを投稿すると、月毎に消えないspecial_pointを獲得でき、他の社員へ贈ることも可能。
- 口コミには「いいね」機能を備え、他の社員の口コミに多様なスタンプでリアクション可能
- 読書記録
- マイページにて自分の読書ログと残point含むuser情報を閲覧可能
- 他ユーザーの読書ログを閲覧可能
- 読書ログはバーチャル本棚としての閲覧も可能
- 日々の読書内容、ページ数、学んだことを記録していける(未実装)
管理者向け機能
- 登録・認証
- 管理者としての登録、ログイン、ログアウト機能
- 口コミ管理
- 社内口コミの閲覧・削除が可能
- 書籍リクエスト管理とポイント設定
- 社員からの書籍リクエストを一覧表示し、管理者が決定・注文
- ポイント管理として、社員ごとの所有ポイントの設定・閲覧・編集が可能 (未実装)
- 書籍と貸出情報の管理 (未実装)
- 社内書籍の一覧や貸出情報、貸出者履歴を管理。書籍の新規追加・編集・削除が可能
カスタマイズ機能
- 社員は、書籍購入の希望先を「会社」または「個人」で選択可能(企業がどちらかのみに絞ることも可能)
- 各企業、月毎に利用可能なpoint数を任意の値に設定可能
- 各企業、口コミを投稿した際に獲得できるpoint数を任意の値に設定可能
非対応機能
- 社員向け
- 口コミへのコメント投稿
- 個別ユーザーへのメッセージ送信
- 管理者向け
- 個別ユーザーへのメッセージ送信
- 社員が投稿した口コミや評価の編集
LibCone開発で前提として意識したこと
前提①:人が明るい気持ちになるような機能を実装したい。
前提②:このアプリは各企業を豊かにするにとどまらず、様々な分野の企業や職種の方にどんな書籍が需要があるのかについてのデータを蓄積できるようにする。将来的にそのデータを分析することによって、各企業、各個人にパーソナライズしたレコメンドを可能にすることを狙う。
蓄積したデータを用いて書籍SNSとしてtoC向けサービスの展開も。(「この企業のこの職種の人が読んだ本」という情報にかなりの価値があると思っている)
前提③:将来的には本屋または通販と契約して企業と書籍の売り手の中間に立つことや、オフィスデザイン会社と契約してオフィスにおしゃれな社内ライブラリを共に提供することなどを狙っている。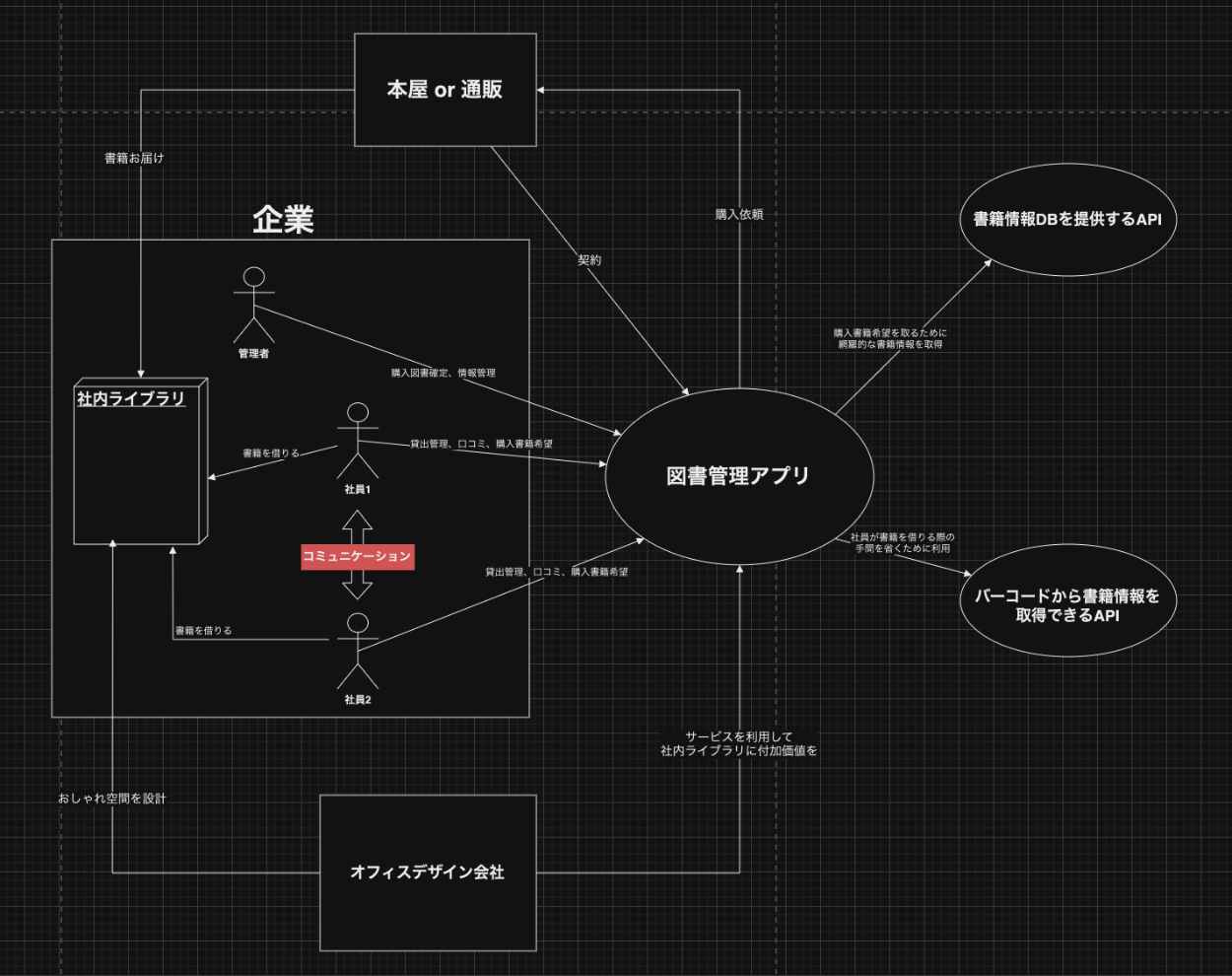
テーブル設計
下記のGitHubリポジトリのREADMEに載っているER図がわかりやすいのでリンクで失礼します。
<工夫した点>
書籍のデータの持ち方
・企業が所持している書籍や、社員に買い与えた書籍などは企業ごとに異なる。しかし、それぞれの企業の書籍テーブルを個々で持ってしまうとテーブル数が増えてしまうし、他の企業と扱う書籍が被っている場合は同じようなレコードが存在してしまい無駄なリソースとなってしまう。そのため、このアプリとして一番の親として書籍テーブルを持っておいて、それと企業テーブルとの中間テーブルとして企業内書籍テーブルを持つことにした。企業内書籍テーブルにはin_officeカラムを設けていて、個人購入希望をしてオフィスには置いていない書籍に口コミをしたい場合でもカラムを false とすれば企業の書籍として扱えるため可能に。つまり、企業が購入or所持した全ての書籍という概念をテーブルとして持った。
・購入リクエストをする際の画面には世の中の全ての書籍が表示されるべきであるが、そんなDBは持ち合わせていないのでユーザーには外部APIを利用した情報を表示させて購入リクエストをとる。ユーザーが企業から購入してもらった書籍が、書籍テーブルに存在していなかった場合にのみ書籍テーブルにinsertしていく仕組みにした。それらの照合は書籍を一意に定めるISBNという国際標準図書番号により行う。
・前提②にもあるように誰がどんな書籍を欲しがっているかという情報はとても価値のあるものなので、分析を可能にするための書籍購入リクエストの処理を考えた。リクエストの情報(ISBN)を受け取った瞬間に書籍テーブルにisbnが一致するレコードがあるかどうかを判断し、なければisbnから楽天BooksAPIを用いて取得した書籍情報を書籍テーブルにinsert。その後、書籍購入リクエストテーブルに書籍idを外部キーとして持たせることでこのアプリ内での分析を容易にした。(どこの企業にはどんな書籍が人気であるか、どの職種の人はどんな書籍を欲しがっているかなどの分析)
また、このテーブル内のレコードを削除するケースとしてはユーザーが誤って購入リクエストを送ってしまった場合に限られるためそのデータは分析には必要ないので物理削除とした。購入リクエストの管理に関しては、購入状況カラムでソートなどすることで可能。
企業テーブルについて
・企業によって毎月の書籍購入補助金額が異なるため、monthly_available_pointsカラムを設けて企業ごとに設定できる仕様にした。
・社内書籍口コミをした場合に獲得できるspecial_pointの値を、review_bonus_pointsカラムに設けて企業ごとに設定できる仕様にした。
ユーザーの職について
・1ユーザーが複数の職を経験している可能性もあるため、ユーザーテーブルと職種テーブルは多対多で持つ。それらの中間テーブルに経験年数カラムを設けることで、この職に就いて何年目のユーザーに人気な書籍などの分析を可能に。
カラムの型について
・書籍購入タイプ(個人購入or社内購入)や、書籍購入状況(購入前、購入申請中、配達済み)などのカラムにおいて、stringではなくintegerで持つことでデータサイズの削減を意識した。少しでもDBのクエリやソートが高速化するような意識を持って設計した。しかし直感的ではないので、ドキュメントにはしっかり記述するべきではある。
API設計
こちらのファイルにyml形式のswaggerを記述しています。
<工夫した点>
ユーザー目線
・このエンドポイントが叩かれる画面では、どんな情報まで表示できていれば満足だろうか?またユーザー目線ではどんな情報が表示されて欲しいかを常に考えてレスポンスを考えた。
・FEで作るロジックとして必要のない無駄な情報を返さないようにすることで、データ転送量が削減されAPIの応答速度を向上させる意識を持った。結果的にUXの向上になると考えている。
(例:社内口コミに関して、書籍詳細画面から見る口コミ内には書籍の情報は含まれている必要はないが、口コミ一覧画面になると書籍情報が必要になる。同じコンポーネントで書けば楽ではあるが無駄なレスポンスを送ってしまうことになるので、コンポーネントを分けてswaggerを書いた)
・万が一のケースや、処理が動かなかったときなどにしっかりと管理者がデータの整合性を合わせることができるような機能を用意することを意識した。
・社内の書籍のバーコードをスキャンすると簡単に書籍を借りることができる機能は、バーコードから取得したISBNから社内書籍を特定できるエンドポイント、ユーザーが社内書籍を借りるエンドポイントの2つを組み合わせることで実現した。
フロント開発目線
・レスポンスの無駄なネストを極力無くしFE開発時にストレスのないようにした。
・レスポンスのキー名はキャメルケースで統一することでjs(ts)の変数名に関してのコーディング規約と一致させた。
技術選定
- Laravel (PHP)
- 授業やインターンで個人開発の時間があまり取れないこともあり、できる限り開発時間を短縮したかった。Eloquent ORMにより、データベース操作が感覚的にできたり、実現したい機能に利用できるメソッドがたくさん用意されている事から速く開発するならLaravelだった。慣れているというのも速く開発できる理由でもあった。
- アプリの性質上、常に活発に使うというようなアプリではなく、同時アクセス数が膨大に増えたり微量な処理速度が大きくパフォーマンスを左右するという場面は考えにくいことから、開発時間をかけてまで静的型付け言語を使う理由もないと判断をした。
- Docker
- 今は個人開発だが今後チームメンバーを増やして開発することになった場合に、全員が同じ環境ですぐ開発できるのが魅力的。
- 開発環境、テスト環境、本番環境が全て同一の構成で動作させることができる。開発者と運用者の環境ごとに依存関係が異なると、正常に動作しなくなる危険性があると思う。
- Nginx
- Laravelでパフォーマンスを妥協した分、webサーバーではApacheより負荷に強いかつ高速なNginxを採用。
- PostgreSQL
- 蓄積したデータから分析をするための機能(RANK関数やROW_NUMBER関数など)を多く持ち、パフォーマンスがMySQLより安定するという情報を見たから。
- 拡張機能をインストールしてデータ分析もできるという情報を見たから(例:pg_stat_statements)
- tsvectorやtsqueryを用いた全文検索機能を使える。単語の形態や意味を考慮した上で検索ができるため、部分一致だけでなく類義語などでの検索も可能。そうなればユーザー体験も向上するはず。ただまだ情報を得ただけの段階なのでこれから詳しく調べて実装したい。
実装での工夫
Laravelを使用しているのでMVCモデルでの開発であるが、Controller部分をServiceクラス(ビジネスロジック定義), Resourceクラス(レスポンス定義), Requestクラスの3つに責務を分け、Controllerクラスでそれらを統合するという実装方針とした。
責務を分けることでのメリットは3つだと考えている。
①Controllerの記述が長くなりすぎる問題の解消。
②各クラスの目的が明確になっているため、チーム全体でコードを把握しやすくなり、修正などするときもどこの何を直せば良いのかが感覚的に分かりやすくなり保守性が向上。
③単体テストが容易になる。Controllerのテストとビジネスロジックのテストを分けて行うことができるため、リファクタの最中にテストが落ちたときにどこの実装が悪かったのかが判断しやすくなる。